
1
/
2
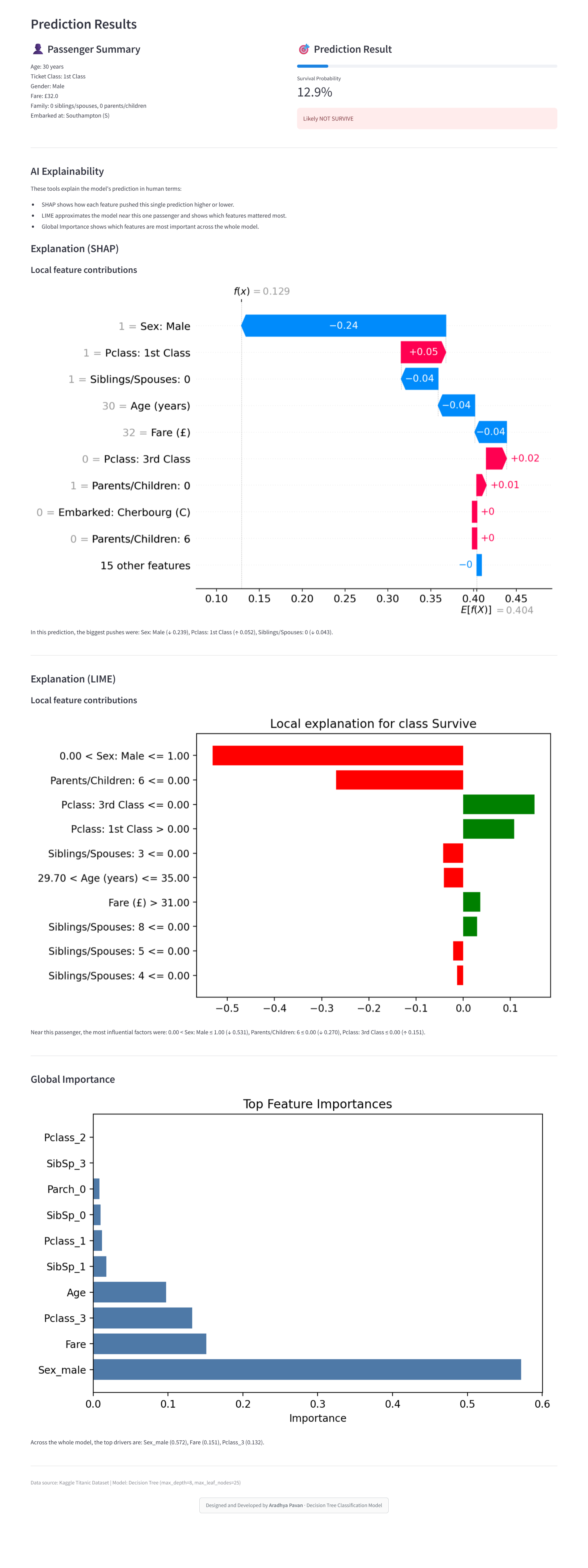
A classic binary classification project to predict passenger survival on the Titanic. It includes data cleaning, imputation, encoding, scaling, and feature engineering (e.g., titles from names, family size, cabin deck). Multiple scikit‑learn models are compared using cross‑validation; the best model is persisted and exposed with a lightweight UI for quick inference.
A reproducible ML pipeline built with scikit‑learn pipelines: preprocess (impute, encode, scale), engineer domain features, train and validate several classifiers, and persist the best performer. A minimal Streamlit UI hosted on Hugging Face Spaces accepts inputs and returns predicted survival with explanatory outputs.
Designed and Developed by Aradhya Pavan H S