1
/
10
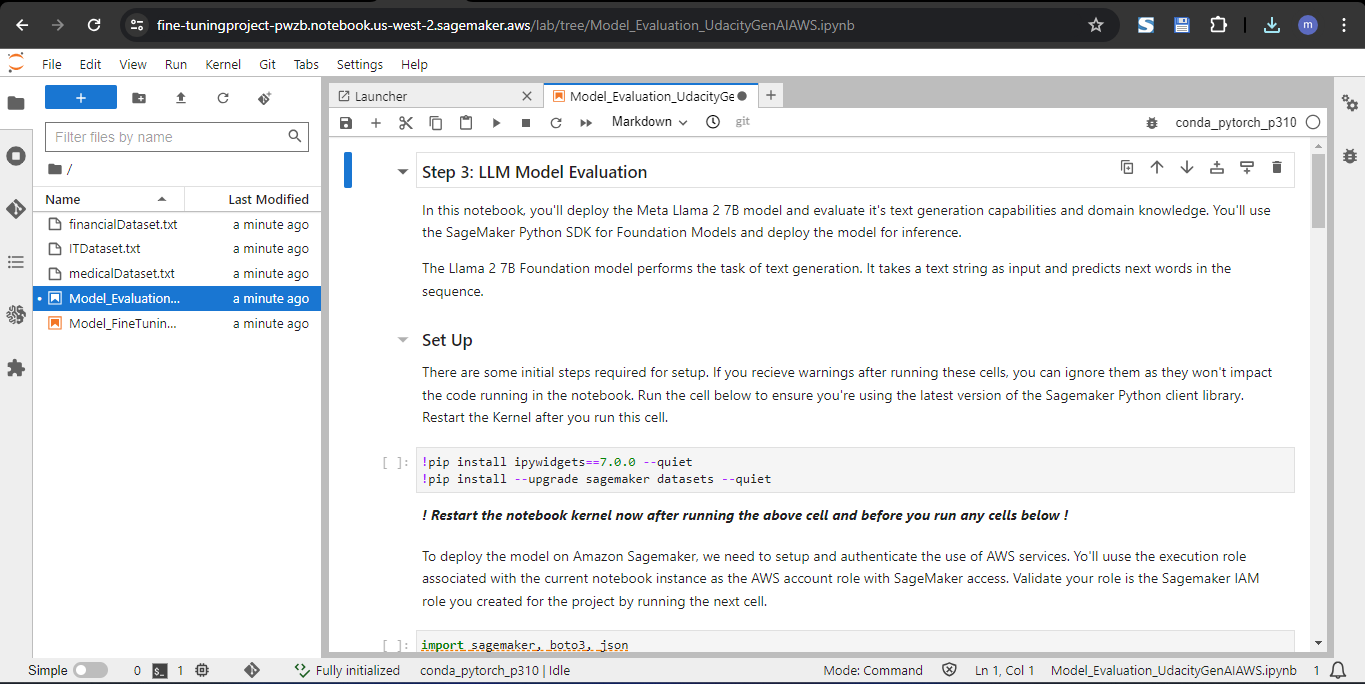
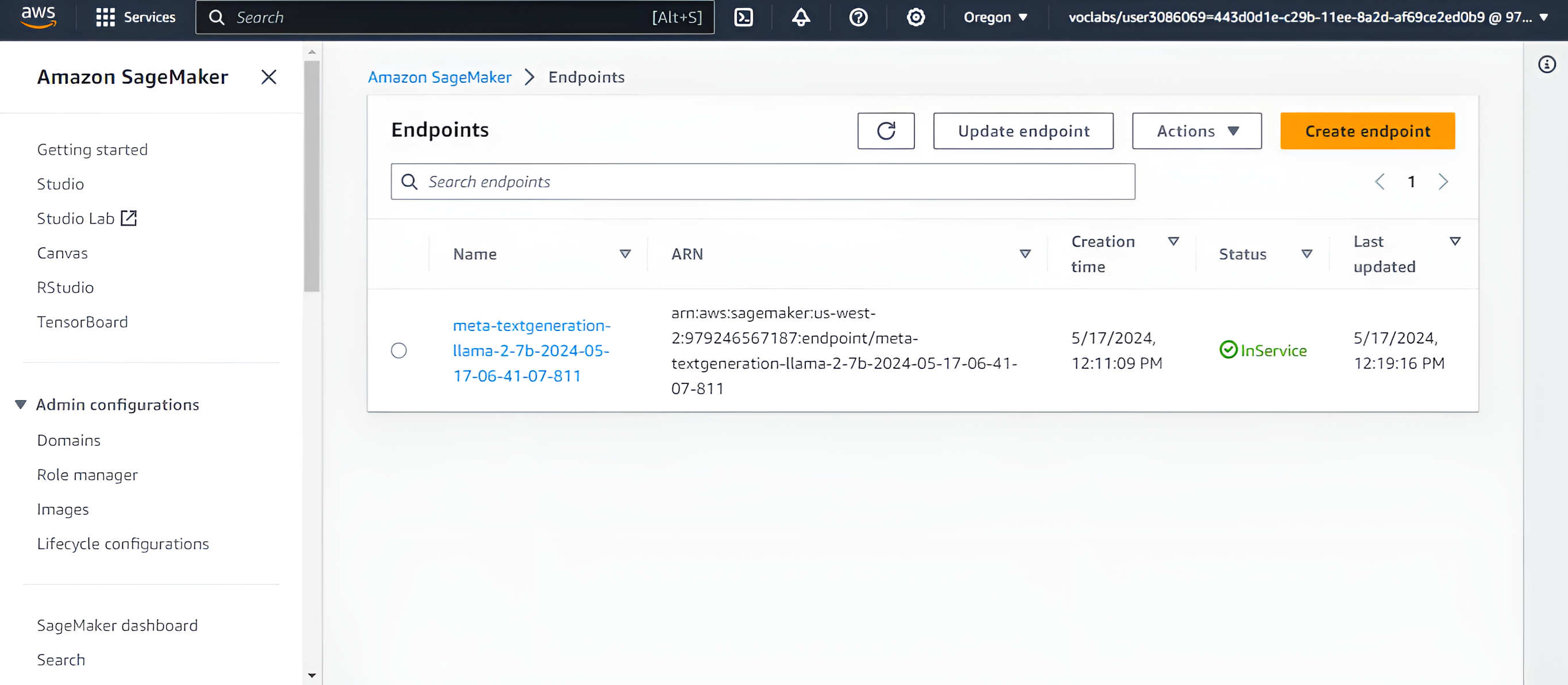
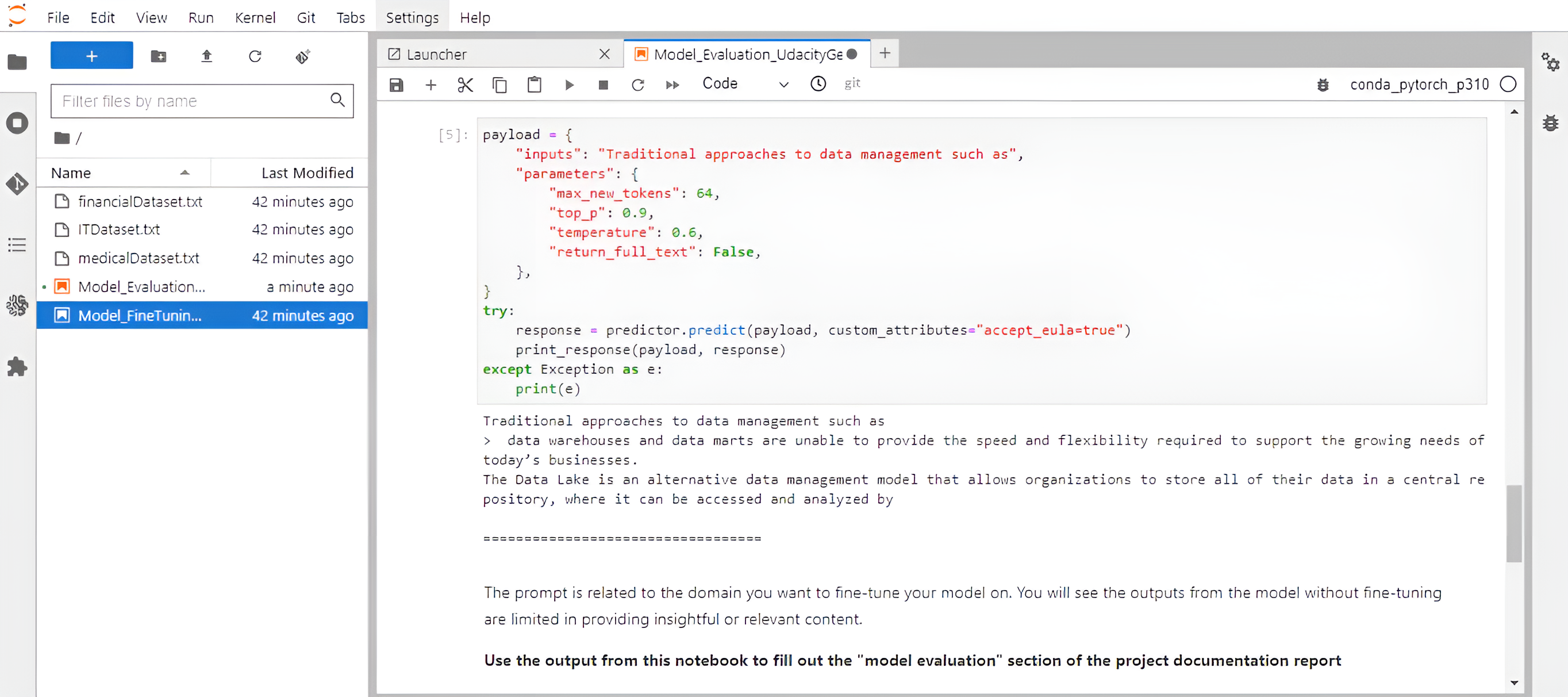
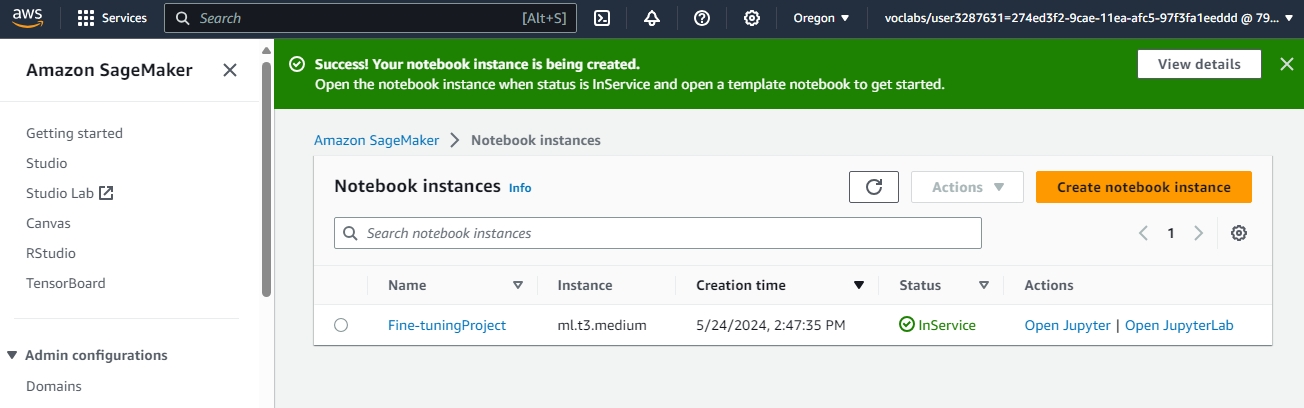
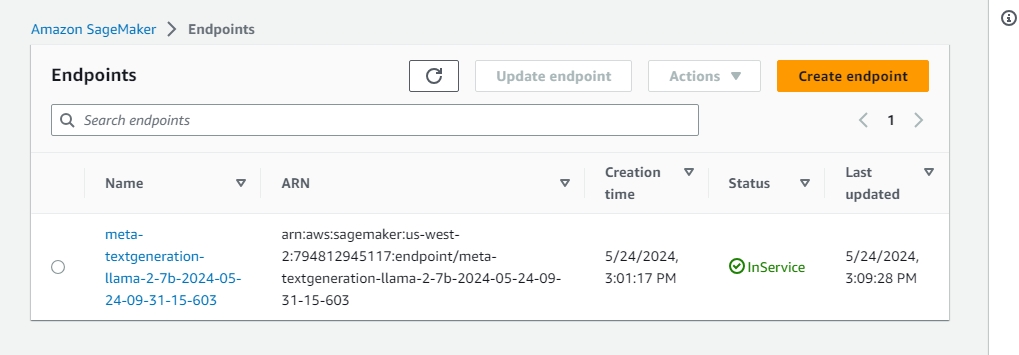
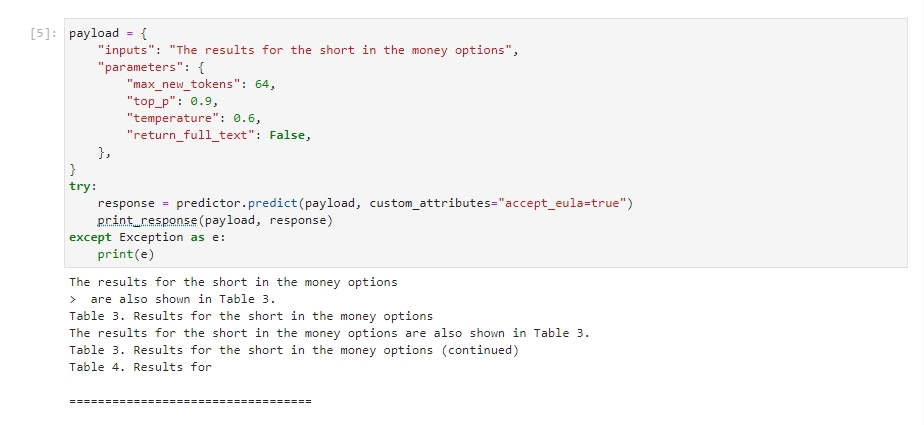
Hands-on Udacity project where I set up AWS infrastructure and implemented a complete Generative AI workflow: model evaluation, fine-tuning, and endpoint deployment using AWS services. Two parallel builds (Project-1 and Project-2) validate repeatability across datasets, including provisioning on EC2, using SageMaker for training/inference, and managing datasets/artifacts on S3. The project emphasizes production hygiene like cost controls and endpoint cleanup.
Provisioned compute on EC2 and orchestrated SageMaker jobs to evaluate baseline model performance, fine-tune with domain datasets, and deploy real-time endpoints. Managed datasets and artifacts on S3, enforced IAM least-privilege access, and automated cleanup of endpoints and resources to control costs. Both project variants (IT and Finance datasets) reproduce the pipeline to confirm robustness.
Repository: Introduction to Generative AI with AWS
Designed and Developed by Aradhya Pavan H S